
Questões sobre Data Mining
Lista completa de Questões sobre Data Mining para resolução totalmente grátis. Selecione os assuntos no filtro de questões e comece a resolver exercícios.
Com relação a data mining e data warehouse, julgue os itens que se seguem. Agrupar registros em grupos, de modo que os registros em um grupo sejam semelhantes entre si e diferentes dos registros em outros grupos é uma maneira de descrever conhecimento descoberto durante processos de mineração de dados.
- C. Certo
- E. Errado
O agrupamento de dados no processo de data mining procura, em uma massa de dados que caracterizam uma população de indivíduos, grupos semelhantes e diferentes. O algoritmo baseado na teoria dos grafos e que dispensa a definição de protótipos utilizado para segmentar a base de dados em diferentes grupos é denominado
- A. K média
- B. K medoides.
- C. Apriori.
- D. DBSCAN.
- E. Árvore geradora mínima.
Julgue os itens a seguir, em relação a data warehouse e data mining. No contexto de data mining, o processo de descoberta de conhecimento em base de dados consiste na extração não trivial de conhecimento previamente desconhecido e potencialmente útil.
- C. Certo
- E. Errado
A respeito de sistemas de suporte a decisão, assinale a opção correta.
- A. As ferramentas de ETL têm como objetivo efetuar extração, transformação e carga de dados vindos de uma base transacional para um data warehouse (DW). No processo de extração, que é o mais demorado dos três, ocorre a limpeza dos dados, a fim de garantir a qualidade do que será posteriormente carregado na base do DW.
- B. Os operadores de navegação drill-down (navegam entre as hierarquias diminuindo o nível do detalhe, por exemplo: município > estado) e roll-up (navegam entre as hierarquias aumentando o nível do detalhe, por exemplo: estado > município) são considerados básicos e estão implementados em todas as ferramentas de OLAP.
- C. As bases de dados criadas para atender ao data warehouse (DW) são do modelo relacional (E/R), em que as tabelas representam dados e relacionamentos e são altamente normalizadas.
- D. Nos processos de análise de inferência, representados pelo data mining, ocorrem buscas de informação com base em algoritmos que objetivam o reconhecimento de padrões escondidos nos dados e não revelados por outras abordagens.
- E. Em uma arquitetura de data warehouse (DW), os dados são coletados das fontes operacionais na fase de extração, trabalhados na fase de transformação (ou staging) e carregados no DW na fase de carga. Quando necessário, um banco de dados temporário, preparatório para a carga no DW, poderá ser criado na fase de extração, com características relacionais.
Acerca de data mining, assinale a opção correta.
- A. A fase de preparação para implementação de um projeto de data mining consiste, entre outras tarefas, em coletar os dados que serão garimpados, que devem estar exclusivamente em um data warehouse interno da empresa.
- B. As redes neurais são um recurso matemático/computacional usado na aplicação de técnicas estatísticas nos processos de data mining e consistem em utilizar uma massa de dados para criar e organizar regras de classificação e decisão em formato de diagrama de árvore, que vão classificar seu comportamento ou estimar resultados futuros.
- C. As aplicações de data mining utilizam diversas técnicas de natureza estatística, como a análise de conglomerados (cluster analysis), que tem como objetivo agrupar, em diferentes conjuntos de dados, os elementos identificados como semelhantes entre si, com base nas características analisadas.
- D. As séries temporais correspondem a técnicas estatísticas utilizadas no cálculo de previsão de um conjunto de informações, analisando-se seus valores ao longo de determinado período. Nesse caso, para se obter uma previsão mais precisa, devem ser descartadas eventuais sazonalidades no conjunto de informações.
- E. Os processos de data mining e OLAP têm os mesmos objetivos: trabalhar os dados existentes no data warehouse e realizar inferências, buscando reconhecer correlações não explícitas nos dados do data warehouse.
Com relação à forma como os dados são armazenados e manipulados no desenvolvimento de aplicações, julgue os itens a seguir. Na implementação de mineração de dados (data mining), a utilização da técnica de padrões sequenciais pode ser útil para a identificação de tendências.
- C. Certo
- E. Errado
Em um processo de Data Mining em um banco de dados, foram considerados dois atributos de clientes de uma organização: diploma (grau de instrução) e renda. Com base nestes atributos o Administrador de BD criou as regras:
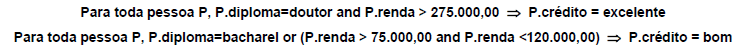
Considerando as técnicas de Data Mining, é correto afirmar que as regras acima
- A. são exemplos de regras de associação baseadas em confiança, em que o antecedente é verdadeiro quando o consequente é verdadeiro, visando, por exemplo, oferecer gratuitamente cartões de crédito aos elegíveis.
- B. são exemplos de regras de classificação obtidas do processo de primeiro encontrar conjuntos de itens com suporte suficiente chamados conjuntos de itens confiáveis, visando, por exemplo, oferecer crédito aos elegíveis.
- C. buscam classificar os clientes objetivando, por exemplo, atender a uma solicitação de cartão de crédito, com base em seu nível de merecimento de crédito.
- D. buscam classificar os clientes com base na técnica de recall, que utiliza como medida a fração de tempo em que o classificador dá a classificação correta, visando, por exemplo, a concessão de empréstimo.
- E. são regras de associação que utilizam a técnica de especificidade, que contabiliza quantas vezes a previsão positiva está correta, visando, por exemplo, a concessão de empréstimo.
Em relação às ferramentas de Data Discovery e os fundamentos de Data Mining, é correto afirmar:
- A. Data Mining é o processo de descobrir conhecimento em banco de dados, que envolve várias etapas. O KDD Knowledge Discovery in Database é uma destas etapas, portanto, a mineração de dados é um conceito que abrange o KDD.
- B. A etapa de KDD do Data Mining consiste em aplicar técnicas que auxiliem na busca de relações entre os dados. De forma geral, existem três tipos de técnicas: Estatísticas, Exploratórias e Intuitivas. Todas são devidamente experimentadas e validadas para o processo de mineração.
- C. Os dados podem ser não estruturados (bancos de dados, CRM, ERP), estruturados (texto, documentos, arquivos, mídias sociais, cloud) ou uma mistura de ambos (emails, SOA/web services, RSS). As ferramentas de Data Discovery mais completas possuem conectividade para todas essas origens de dados de forma segura e controlada.
- D. Estima-se que, atualmente, em média, 80% de todos os dados disponíveis são do tipo estruturado. Existem diversas ferramentas open source e comerciais de Data Discovery. Dentre as open source está a InfoSphere Data Explorer e entre as comerciais está a Vivisimo da IBM.
- E. As ferramentas de Data Mining permitem ao usuário avaliar tendências e padrões não conhecidos entre os dados. Esses tipos de ferramentas podem utilizar técnicas avançadas de computação como redes neurais, algoritmos genéticos e lógica nebulosa, dentre outras.
Julgue os itens subsequentes, acerca dos conceitos de data mining, data warehouse e sistemas colaborativos. Em data mining, a técnica boosting é utilizada para fazer a seleção inicial dos dados a serem analisados durante o estágio de construção do modelo.
- C. Certo
- E. Errado
No que se refere a computação em cluster, julgue o próximo item. Na constituição de um cluster, é possível a utilização de sistemas operacionais diferentes, entretanto, desktops domésticos ou de escritório não são permitidos como nós do cluster.
- C. Certo
- E. Errado

O Provas e Concursos é um banco de dados de questões de concursos públicos organizadas por matéria, assunto, ano, banca organizadora, etc
